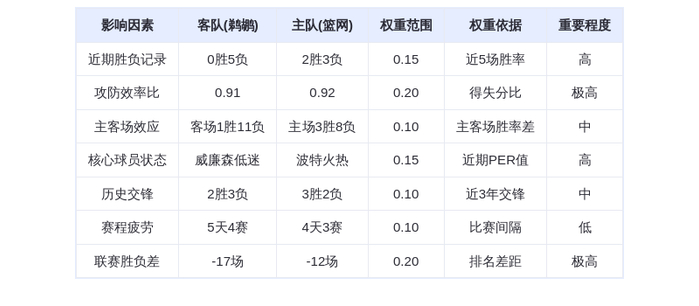
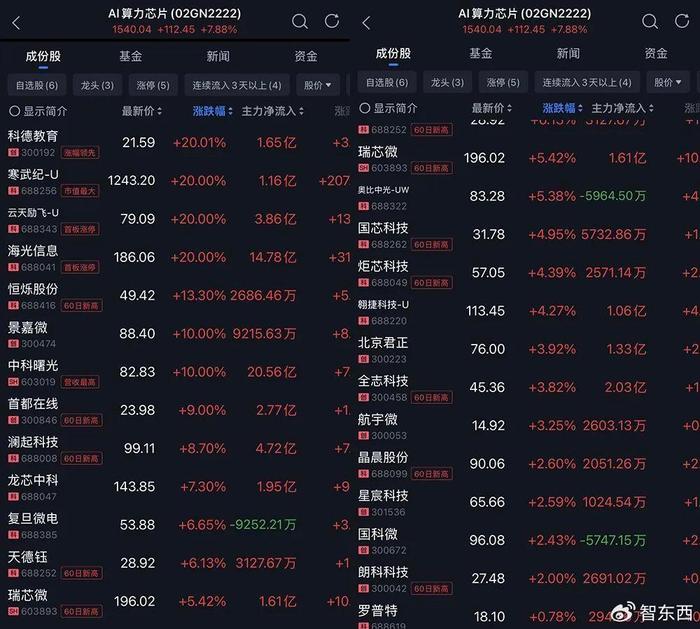
DeepSeek的“掀桌”:一场关于算力定价权的终极反击
昨晚英伟达股价大跌5.46%,北美算力板块全线崩溃。这并非源于财报暴雷,而是因为DeepSeek在发布V4模型前,拒绝向英伟达提供早期优化权限,转而将首发适配权全盘交给了华为等国产芯片厂商。
这一举动,直接撕碎了AI行业过去十年的“潜规则”。过去,全球模型发布前必须“拜码头”,先让英伟达工程师调优,确保在CUDA生态里跑得最快。DeepSeek这次不仅没拜,还反手把门关上了。
老美之所以破防,是因为DeepSeek联手清华、北大发布的DualPath推理框架,解决了AI推理的“便秘”问题deepseek。
痛点:大模型对话越长,翻阅的缓存(KV Cache)就越长。数据在硬盘和显存之间搬运,导致算力空等(GPU气泡),反应慢半拍。
解法:DualPath采用“边加载、边计算”的双路径机制。它把数据先发给闲着的解码引擎,再通过RDMA高速网络甩给预处理引擎。
效果:这就像超市结账,先把蔬菜水果称重好,最后统一扫码。在线服务并发数直接提升1.96倍,成本腰斩。
这背后是算力出海的隐形贸易。老美的程序员发出API请求,数据通过太平洋光缆传到中国数据中心,用我们的算力和电力完成计算,再传回美国。因为Token没有实体,海关无法统计,报表上体现不出来,但算力和电力,就这样完成了出海。
同行补刀:Anthropic(开发Claude的公司)指责DeepSeek的技术是“蒸馏”它的回复,属于“工业级盗窃”。原文出处:DeepSeek的“掀桌”:一场关于算力定价权的终极反击,感谢原作者,侵权必删!