

自变量:具身模型不是把DeepSeek塞进机器人
。虽然自变量是一家软硬一体的公司,但这场融资背后,真正说服投资人的可能是他们对于机器人「大脑」的思考。
和之前的 locomotion(移动)、navigation(导航)战场不同,「大脑」所主导的 manipulation(操作)涉及频繁的物理世界交互,随机性、不确定性充斥着每一个看似简单的任务。这也是为什么,在我们看了多年的机器人跳舞、跑酷、玩杂技之后,机器人在自主操作上依然没有拿出一个技惊四座的 demo。而这个「自主操作」,才是决定机器人能否大规模走入人类世界的关键。
在自变量看来,「操作」这类任务的复杂性决定了,机器人必须有一个由「物理世界基础模型」所支撑的「大脑」。这个「大脑」不是像很多人想的「把 DeepSeek 塞进宇树」那么简单,它不是 AI 模型的「应用层」,而是独立、平行于语言大模型、多模态模型等虚拟世界模型的新范式。
对于这个新范式应该是什么样子、如何去打造,自变量已经有了一套体系化的方法论,并且自研出了一些成果。这些大胆的尝试,或许会为具身智能领域带来新的变量。
我们知道,最近几年机器人「大脑」的进化主要还是依赖语言模型和多模态模型。于是很多人就认为,具身智能是 AI 模型的一个应用方向。但自变量 CEO 王潜曾在多个场合强调,这个定位存在偏差。
举例来说,图中有两个矿泉水瓶,一个瓶盖拧紧,一个没有完全拧紧。只靠视觉去看,它们在图像里差别很小,但一旦把它们拿起来、翻转或倾倒,结果却完全不同 —— 一个会漏水,一个不会。
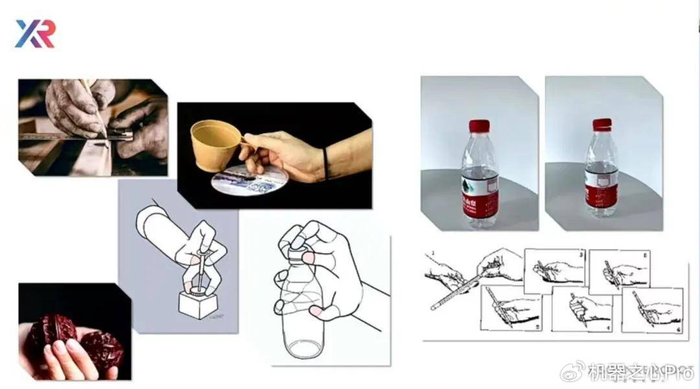
物理世界里真正关键的信息,往往就藏在这些「看不出来但会影响行为」的细节中。这些差异只有在与世界发生真实交互时才会暴露出来,而不是静态观察就能轻易判断。
更重要的是,这类信息往往并不会在当下立刻给出反馈。比如拧瓶盖这个动作本身,并不会产生任何可见变化,真正的差异要等到下一步、甚至再下一步操作时才显现出来。对模型来说,这意味着它必须能够把一连串感知、动作和结果在时间上串联起来理解,而不是只处理某一帧画面、某一个瞬间的输入输出。
这正是物理世界对智能提出的一个隐性要求:模型不仅要能感知,还要能处理足够长的行为序列,理解因果是如何在时间中逐步展开的。否则,它就永远学不会那些「现在看不出来、但之后会出问题」的物理规律。
而在很多真实任务中,问题甚至不只是时间跨度变长这么简单。机器人往往需要在行动之前,对未来进行某种形式的推演。比如在倒水之前,它需要判断瓶子会不会漏;在整理桌面之前,它需要决定先拿走什么、再放回什么。这类判断并不是对当前状态的直接反应,而是对「接下来会发生什么」的内部演算。
也正因为如此,单纯依赖静态信息训练出的语言模型或多模态模型,在物理世界里往往显得力不从心。它们并不真正理解「拧紧」和「没拧紧」在物理后果上的差别,也难以应对充满连续变化、随机扰动和部分不可观测的现实环境。
在自变量看来,这并不是靠给现有模型打补丁就能解决的问题,而是指向了一个更底层的结论:我们需要一种「生于物理世界、用于物理世界」的基础模型。这种模型应当与语言模型、多模态模型平行存在,而不是作为它们的下游应用。自变量的目标,正是要打造这样一个基础模型。
一是要有一个统一的架构,因为真正的物理智能需要的是整体性的、具身的理解,而不是模块化的知识拼接。
举个例子,人类在使用锤子时,注意力不在「这是一个锤子」「锤子有多重」,而是在木头、钉子和要完成的目标上。锤子作为一种工具,会被纳入行动本身,在认知中「隐退」。但对于现在很多机器人来说,情况恰恰相反,每一次使用工具,它们都要重新经历一整套流程:看见这是锤子,理解锤子的用途,规划怎么用,再执行动作。自变量认为,这种方式永远无法达到人类那种直觉的工具使用境界。
归根结底,这种局面是把模型拼接起来的分层架构所带来的 —— 视觉模块先把世界压缩成向量,语言模块再接手理解,规划模块再根据语言输出动作。一套流程下来,模块之间彼此「看不见」「听不见」对方真正关心的东西。每跨一次模块,细节、关联和物理直觉都会被削掉一层。这就像把一幅油画描述给盲人,再让盲人转述给聋人。
这就不难解释,为什么自变量从成立第一天就是「端到端」路线的坚定信徒。他们看到的是这一路线的底层逻辑:信息必须在一个统一的空间里流动,系统才能发现不同东西之间深层的关联deepseek。早期,这一选择饱受质疑,但如今,Google Robotics、Physical Intelligence 等头部具身智能团队也都走到了这条路上。
这条路已经被语言模型走过一遍。大家发现,相比于最初针对单一任务分别做专用模型,把翻译、问答、写作、推理等任务放进同一个模型里,反而能让模型学到更底层的逻辑和常识。物理世界也是一样,当模型同时学习足够多、足够杂的任务,它会被迫去发现这些任务背后的共性结构 —— 物理规律、物体属性、因果关系。一旦掌握了这些共性,模型学新任务所需的数据量就会骤降,甚至出现「涌现」。
提到语言模型,它的成功其实还有一个常被忽视的关键:它找到了一个极好的损失函数 —— 预测下一个词。这个看似简单的目标,能够把海量文本中的结构、逻辑、常识全部压缩进模型里。
自变量认为,不能只停留在「预测动作」。如果只预测动作,模型很容易沦为一个「模仿者」,它只学会了手势的形状,却不懂得背后的原因。真正的突破口在于:将损失函数从「动作预测」升级为「多模态状态的预测」。
当模型试图预测「如果我推倒这个杯子,下一秒视觉画面会如何变化、指尖的触感会如何消失」时,它实际上是在强迫自己理解因果律,把物理世界的复杂性压缩进模型里。
这也解释了为什么自变量的 WALL-A 模型不只输出动作。它还能用语言和人对话,能根据图片重建三维环境,能像世界模型一样预测未来。这些能力看似五花八门,但背后的逻辑是一致的:如果一个模型真正理解了物理世界,它就应该能用各种方式表达这种理解,无论是控制机械臂,还是描述它在做什么,还是预测物体会怎么滚动。在这个模型身上,我们已经能够看到自变量所追求的物理世界基础模型的雏形。

在国内,这种活动也是非常有益的尝试,因为从语言模型发展来看,整个技术社区的发展离不开开源文化,具身智能领域也需要自己的 DeepSeek。
一个可能的答案是:语言本身就是一种高度压缩的符号系统,人类已经用几千年的时间把世界的复杂性「预处理」成了文字。模型要做的,只是学会这套现成的编码规则。但物理世界没有这样的捷径。重力、摩擦、碰撞、形变,这些规律从未被谁显式地写下来,它们散落在每一次交互的细节里。
这也意味着,物理世界基础模型的构建,某种程度上是在重走人类婴儿的路。物理世界基础模型要学的,是那些人类「做得出但说不清」的东西,这可能才是智能更本源的形态。原文出处:自变量:具身模型不是把DeepSeek塞进机器人,感谢原作者,侵权必删!
