比DeepSeek贵了400倍,GPT-5.2想钱想疯了?
这么说吧,这家伙或许是最适合打工人的AI,因为它很可能开启了 AI 从人类助手到专家的转变。
首先是在专业知识上,GPT-5.2 有 7 成的把握,能打败正在屏幕前,刷视频的各位行业专家们。
只看跑分的话,这次的 GPT-5.2 在各个维度上,都要比 Gemini 3 Pro 高了那么一点点。
这是他们在今年的925提出来了的一个全新测试方式,用来衡量 AI ,能否真的来帮打工人完成工作。
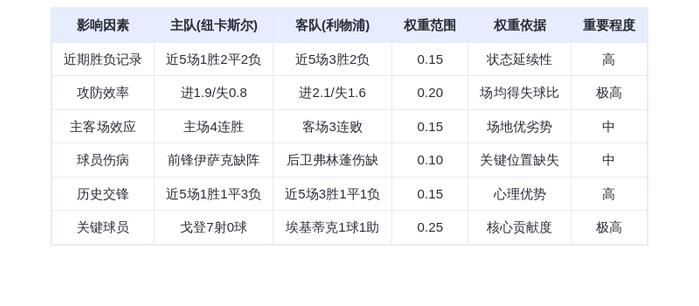
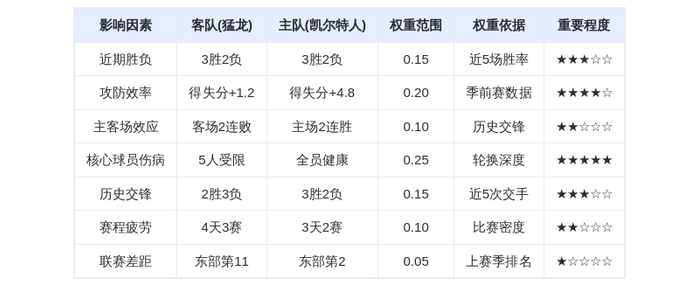
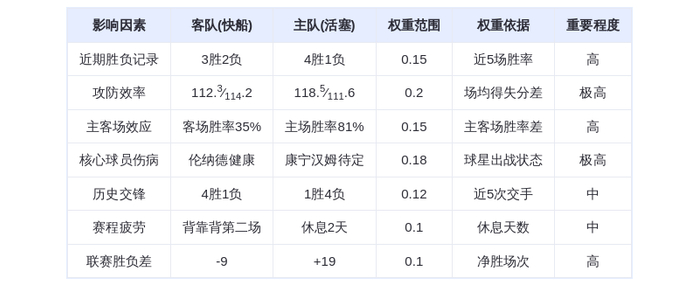
咱们也简单的体验了一下这个新模型,让 GPT-5.2 去互联网上统计这些 AI 公司发布的所有模型。
结果在整整 14 分钟的思考后。GPT-5.2 成功的帮咱们把这一系列数据收集,结果统计,表格绘制的任务都给完成掉了。
除此之外,GPT-5.2还能完成一些复杂的表格工作,做出来的表格不但比过去的自己做的表格要美观许多。
我们也简单的测试了一下,但可能是因为有了 Gemini 珠玉在前的缘故,GPT-5.2 给我的感觉,就有那么一些平平无奇了。
同样一句话做出来的小游戏,Gemini 已经开始考虑各种时髦的配色了,GPT 还在刷大白墙,做毛坯房。
有人在测试的时候发现,让 GPT 写 50 个创意,它就会认认真真的去写 50 个创意,而不是像过去的模型一样deepseek,写 10 个点子就开始摆烂。
除此之外,在上下文能力上方面,OpenAI 也补强了一波,在插针实验中,即便是文本长度到了 256K,成功率依旧是接近百分之百。
比如在官方展示的图像识别案例上,大伙们发现,Gemini 3 Pro 的颗粒度直接爆杀 GPT 5.2.
比如 Gemini 可能在全模态领域一骑绝尘;GPT 在逻辑推理、生产力方面,也依旧走在同行前头;Claude 则在代码能力和写作上,继续遥遥领先。
毕竟在怎么实现 AGI 这个问题上,大厂们的差异已经凸显。谷歌可能觉得,多模态能感知世界才是未来;OpenAI则信仰极致的逻辑推理和生产力的提升;Anthropic 认为高维度的语义理解和对齐,才能通往 AGI。
反正 AI 大哥位置轮流坐的现状,还在继续,按顺序来,下一个出招的应该是Anthropic 了。原文出处:比DeepSeek贵了400倍,GPT-5.2想钱想疯了?,感谢原作者,侵权必删!