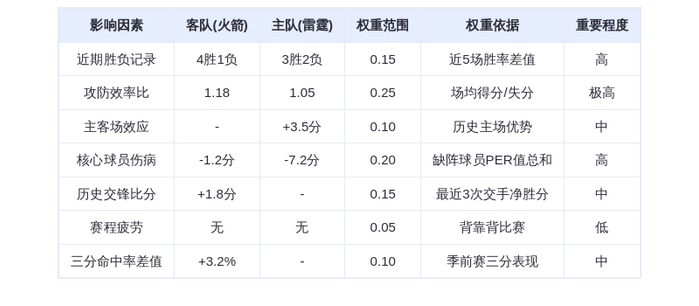
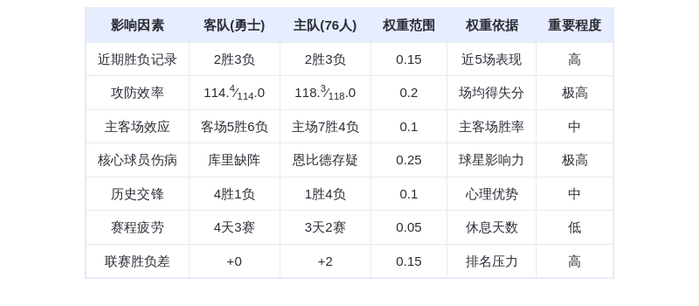
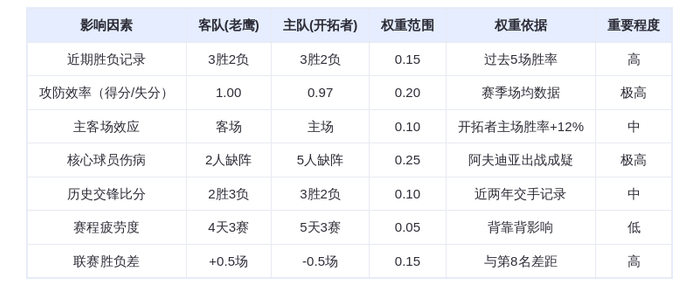
DeepSeek的GRPO会导致模型崩溃?看下Qwen3新范式GSPO
在 LLM 后训练阶段,似乎是一个强化学习的特殊形式。用于大语言模型(LLMs)微调的强化学习(RL)算法正沿着一条明确的演进路径持续发展。
起初,OpenAI 开创了一种名为 基于人类反馈的强化学习(RLHF)的技术,用于改进 ChatGPT。RLHF 的核心是让人类标注员对模型生成的多种响应进行打分,并选出最优答案作为训练参考。这一过程虽然有效,但也耗时、昂贵且依赖人力,通常需要一支小型但专业的数据标注团队。
DeepSeek 的重要创新在于用 RL 技术自动化了这一环节。算法不再依赖人工逐一评估,而是让模型在探索过程中,通过获得「奖励信号」自主学习正确行为,从而显著降低了成本,提高了效率,最终能以较低的成本实现高性能。
在几个月前Qwen3 首次亮相的时候,其旗舰模型的性能就已经与 DeepSeek-R1、o3-mini、Gemini 2.5 Pro 等顶级模型表现相当。除此以外,Qwen3 系列模型覆盖了 MoE 模型和密集模型,每一款模型又有许多细分版本。
最近,Qwen 团队发布了一篇有关其模型后训练算法的论文,似乎揭示了 Qwen3 模型成功的核心技术细节。
最近 Qwen 的研究表明,使用 GRPO 训练大语言模型时存在严重的稳定性问题,往往会导致模型不可逆地崩溃。他们认为 DeepSeek 的 GPRO 方法存在一些严重问题:
这一问题在 专家混合模型(Mixture-of-Experts, MoE) 中尤为严重,因为token 级别的路由变化会加剧不稳定性。
为缓解这一问题,基于 GRPO 的训练流程通常需要依赖一些额外策略,例如 路由重放(Routing Replay)。
因此,Qwen 团队声称 GRPO 的 token 级重要性采样无法达到稳定训练,其优化目标是「病态的(ill-posed)」。
Qwen 团队指出,GRPO 的不稳定性源于其对 token 级重要性采样权重的错误使用。在强化学习中,重要性采样(Importance Sampling)用于校正行为策略(即用于收集训练数据的策略)与目标策略(当前正在优化的策略)之间的差异。
当两者不一致时,重要性采样通过为已有数据样本赋予权重,使其更能代表当前希望优化的目标策略,从而提高训练的稳定性与有效性。
在大语言模型(LLMs)的训练中,强化学习常常会复用旧策略生成的响应,以节省计算资源,这属于典型的「离策略」(off-policy)训练场景。重要性采样正是用于缓解这种策略不匹配带来的影响,并帮助稳定训练过程。
然而,GRPO 将重要性采样的权重应用在每一个 token 上,而非整个生成的序列。这种做法会带来显著的方差,并在生成较长序列时造成「误差积累」与「训练不稳定性」。
Qwen 团队指出,当在训练目标中应用此类重要性权重时,由于每个 token 的比值是独立计算的,会导致高方差的累积,从而破坏梯度稳定性,最终引发模型崩溃。
同时,这种做法会将高方差噪声引入训练梯度中,尤其在长序列上呈现累积效应,并且在存在「裁剪机制」时,这种不稳定性问题会进一步加剧deepseek。
在所有展示的实验场景中,其新提出的算法 GSPO 均表现出比 GRPO 更高的训练效率。在 CodeForces 任务中,GRPO 的最终得分收敛于 2000 分以下,而 GSPO 随着训练计算量的增加持续提升成绩,展现出更强的「可扩展性」。
正如其名称所暗示的,GSPO 的核心在于将重要性采样从 token 级转移至序列级,其重要性比值基于整个序列的似然度计算:
这种采样权重的设计自然地缓解了逐 token 方差的累积问题,从而显著提升了训练过程的稳定性。
需要注意的是,指数中的因子用于「长度归一化」。如果不进行长度归一化,仅仅几个 token 的似然变化就可能导致序列级重要性比值的剧烈波动,而不同长度的生成响应在目标函数中也将需要不同的裁剪范围,这会进一步增加训练的不稳定性。
由于 MoE 模型具有稀疏激活特性,这会在使用 GRPO 时进一步加剧训练过程中的不稳定性。在经过一次或多次梯度更新后,相同响应所激活的专家网络可能发生显著变化。
Qwen 团队在使用 GRPO 训练 48 层的 Qwen3-30B-A3B-Base 模型时发现:在每一次强化学习的梯度更新后,对于相同的 rollout 样本,新策略所激活的专家中约有 10% 与旧策略所激活的专家不同。这实际上意味着,每次梯度更新后,你都在用不同的数据样本训练不同的模型,毫无疑问这是一种极其低效的训练方式。
在引入 GSPO 之前,为缓解这一问题,他们甚至采取了一种名为「Routing Replay」的技巧,即强制目标策略激活与旧策略相同的专家网络。
相比之下,GSPO 无需使用 Routing Replay 也能实现稳定收敛,从而消除了不必要的训练复杂性,并保留了 MoE 架构的全部潜力。
显著降低了方差,同时消除了对「路由技巧」(如 Routing Replay)等辅助策略的依赖;
业界已普遍达成共识 —— 在大语言模型的后训练阶段引入强化学习,对于提升其推理能力至关重要。
而论文中的大量实验结果也进一步证实,GRPO 所采用的「逐 token 重要性采样」方法存在不稳定性和低效性的问题。原文出处:DeepSeek的GRPO会导致模型崩溃?看下Qwen3新范式GSPO,感谢原作者,侵权必删!